
Hi! I’m Philippe
Cambodian-born French
Software Engineer, Products Maker
Entrepreneur in Japan, Tokyo
Products built
SewaYou
Practice a language in real life with native people around you (Android & iOS app)
filipyoo.com
Personal programming blog about Data Engineering/Science and various pet projects
Blog

Plot and visualization of Hadoop large dataset with Python Datashader
Data is beautiful 🤙

Handle 200 GB of data with AWS EC2 Hadoop cluster
First time to deal with this kind of big size

Set up Hadoop multi-nodes cluster on AWS EC2: a working example using Python with Hadoop Streaming
Welcome to the cloud and big data world

Multi-Objectives Shortest Paths Algorithms for the Multi-Transfer flight routes
A little bit of mathematics here, but nothing to be scared of...
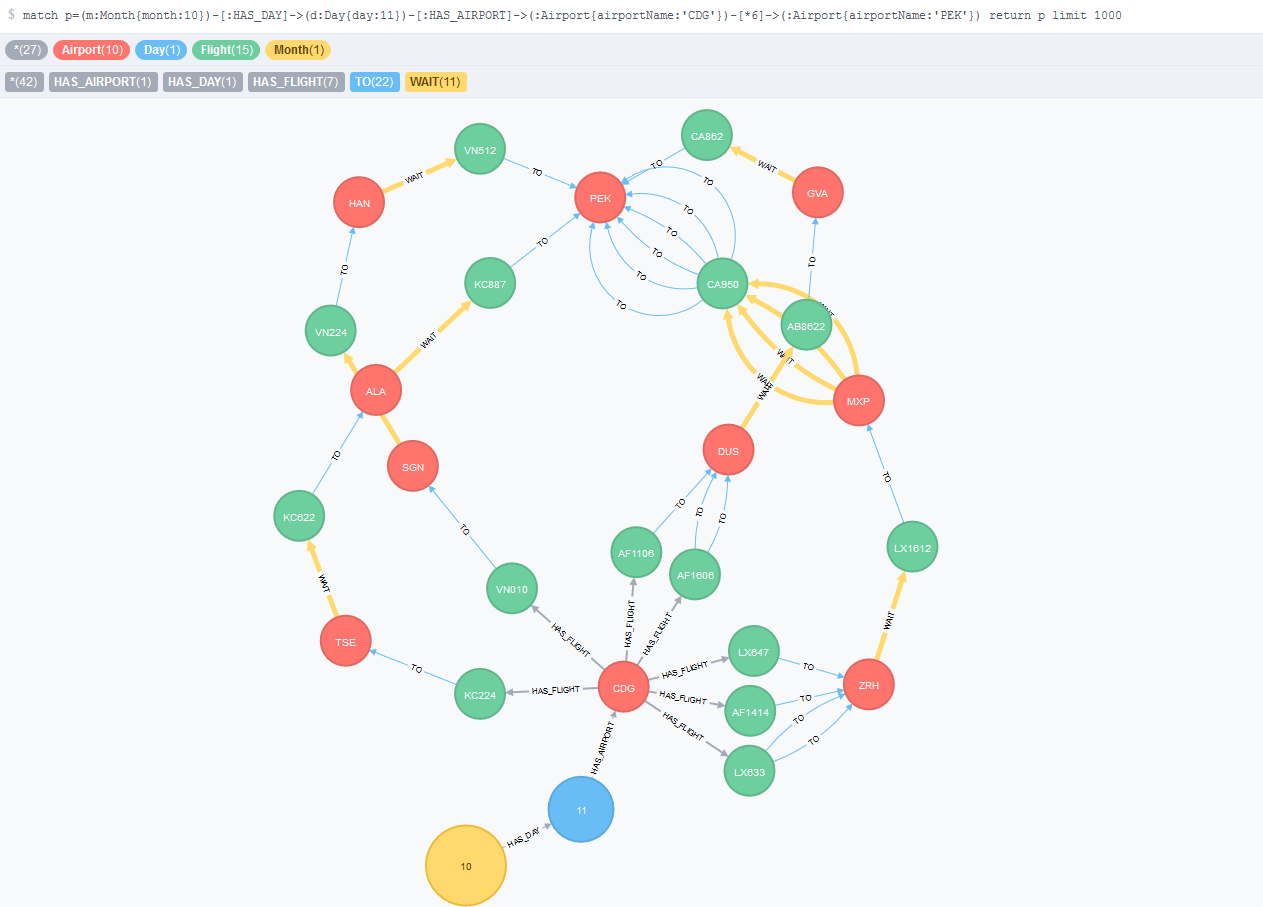
Different models for Multi-Transfers flight routes using Neo4j
Modeling the data structure is a crucial task when working with data

Designing flight routes problem - Migrating from MySQL to Neo4j
Diving into Graph Database...
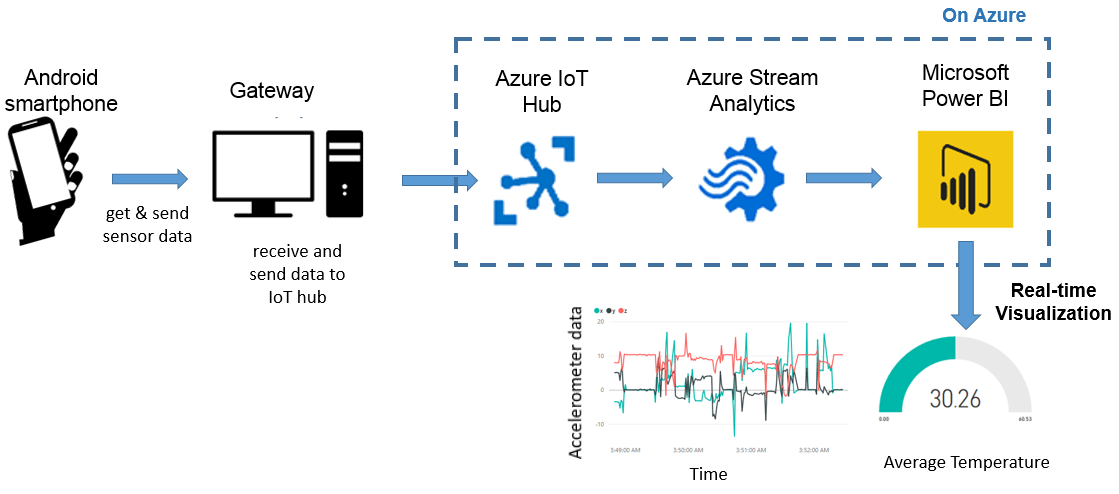
IoT: Send Android smartphone sensor data to Microsoft Azure Cloud
Welcome to the exciting world of IoT

Learn Data Science with Kaggle using Python
Following the trend... let's get some Data Science knowledge!

Topic and sentiment analysis using Twitter API
Yet another good example of using third party API

Add lyrics to MusixMatch using API: scraping lyric for songs without lyrics
Leverage programming to contribute to the musical world!
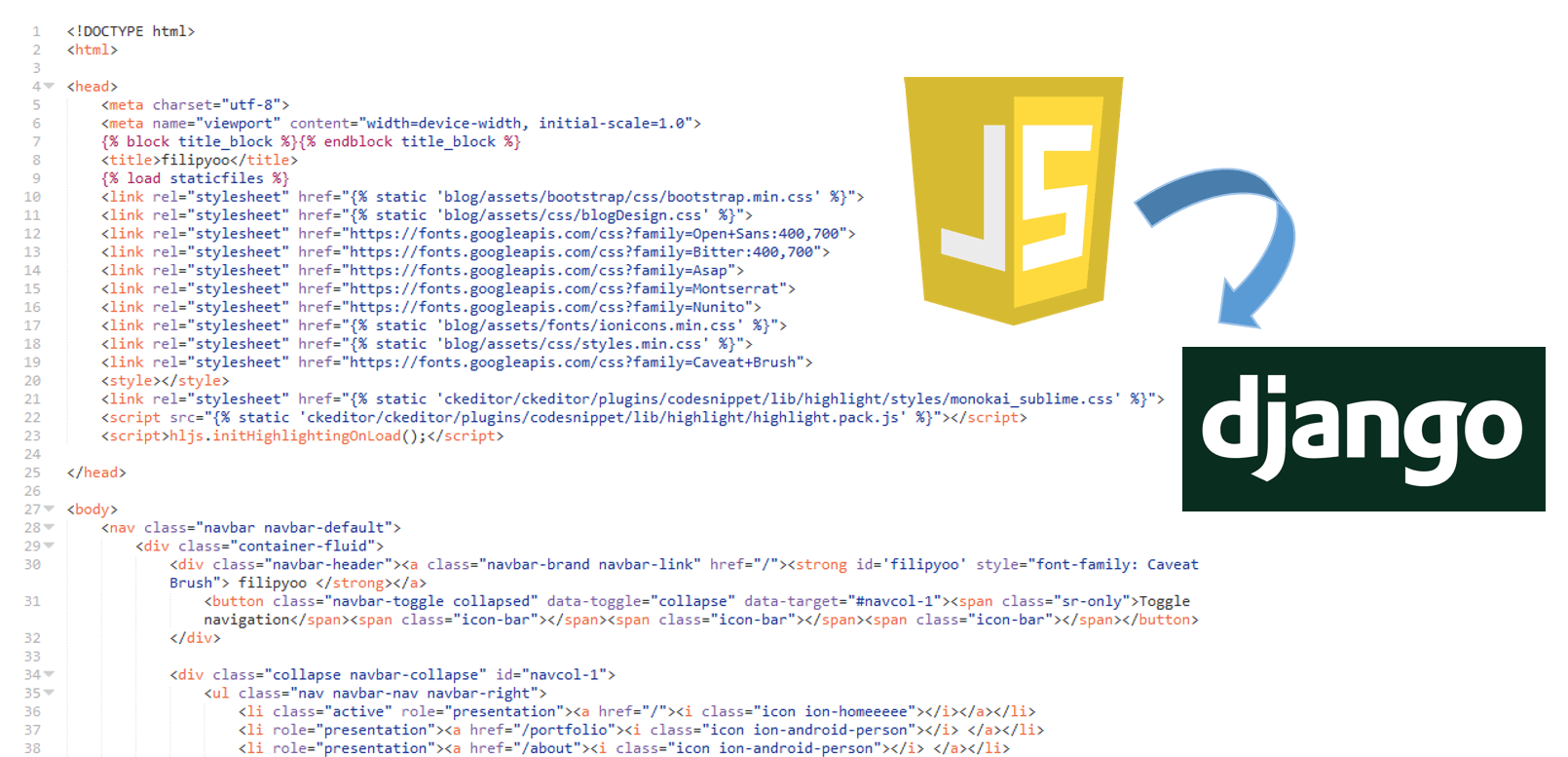
Accessing Django template variables from external JavaScript files
Quick example and code snippet on how to do that

Simple Android application to read Lang8 webscraped posts.
Just building a CRUD Android app

Create a GUI to read Lang8 webscraped posts using Python PyQt
First diving into making GUI
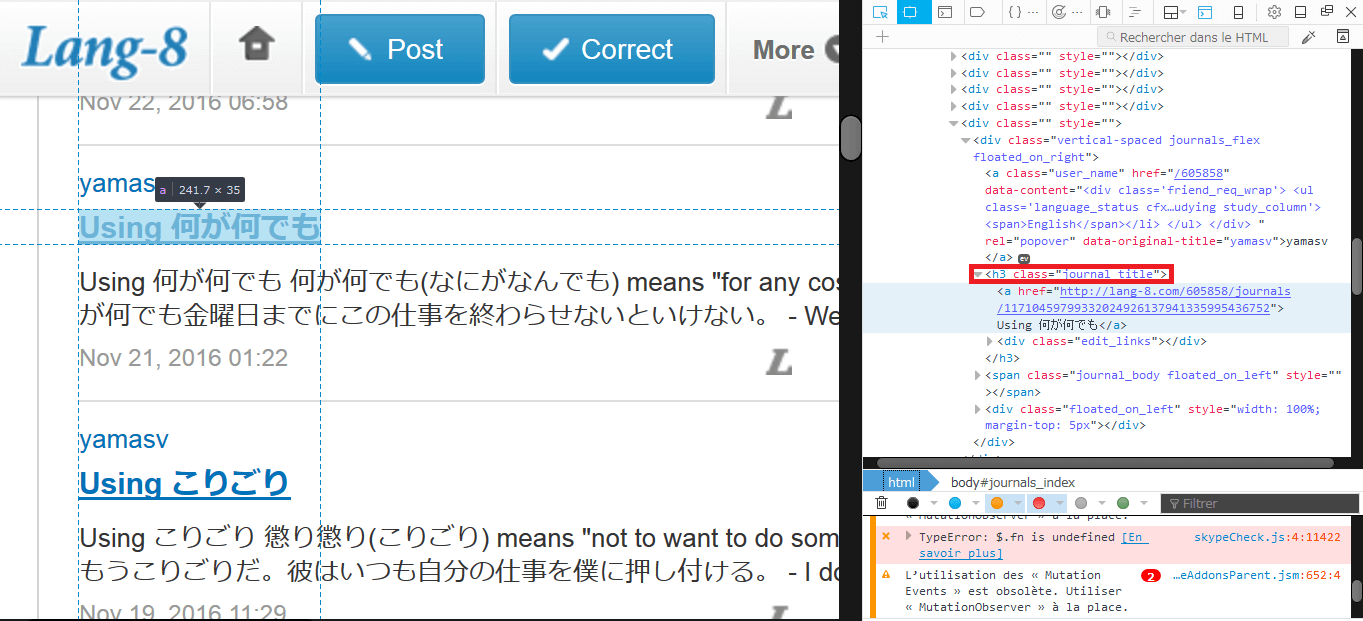
Web Scraping : get all the posts of your favourite user on a website with Python.
Watching your script running by itself is such a good feeling...!
Autodownload/rename your photos on Google Drive with Python.
First usage of an external API!
Autoplay the latest episode of your favourite TV series with Python.
When you're too lazy to remember when was the last episode you've watched




© 2020, Philippe Khin