

As explained in the previous post, the Hadoop ecosystem can be installed manually (often called vanilla Hadoop) in order to see how things are tied together and how MapReduce's parallelism works. But when it comes to deal with a large amount of data, in order to avoid the installation and configuration overhead, you would probably better use one of the Hadoop popular distribution such as Cloudera, Hortonworks or MapR.
The problem when dealing with a great amount of large files can be break down into three steps:
- Get or download the dataset
- Store it in a persistent way
- Analyze the data
To describe these steps, I will use the publicly available NYC taxi dataset and the Cloudera Hadoop distribution. I chose this dataset because it's publicly available, big enough (more than 200 GB, composed only with not more than 3Gb CSV files, which represent a total of more than 1.3 billion rows), and it's structured. As a first step, it's better to start with a well structured dataset so you don't have to deal with preparing the data.
This project will use the following:
- AWS EC2 instances (m4.large x4, 1 Master and 3 slaves nodes)
- AWS S3, to store the entire dataset persistently
- Cloudera CDH 5.12, the Hadoop distribution to be installed on each nodes automatically managed by the Cloudera Manager
- Hive, the data warehouse to manage large dataset residing in distributed storage using SQL.
- Hue, the Web UI to query data in the cluster.
Download the dataset
The NYC taxi dataset includes records of three types of taxi from 2009 to 2016: yellow, green (only available starting from August 2013) and FHV (Uber taxi, only available starting from January 2015). Since the FHV is not big and rich enough (only a few number of fields), I only deal with the green and yellow taxi dataset.
Download using Python's Requests to a hard disk
My first download was to write on my laptop (and not on a EC2 instance) a python script using the Requests package and keep the dataset in my 1TB hard disk. The key point here is to use the streaming mode, and write the file content chunk by chunk. The method works but is really slow: it took me around three entire days to download 215 GB at an average speed of 1.5~2Mb/s. I then wanted to upload these files into my S3 bucket, and the process speed is even slower: around 300Kb/s. It would take forever to upload more than 200Gb of files. I've used tools like the official AWS CLI, s4cmd, or S3 Browser, but it didn't speed up that much. It might be because I live in France, and the dataset is in a USA bucket and of course, my network performance. So I decided to try out with a EC2 Instance instead.
Download using AWS EC2 Instance
To my big surprise, it turns out that downloading a file with a m4.large EC2 Instance is sooo fast: an average of 50Mb/s !!
So I increase the EBS size of my instance to 250 GB, big enough to temporarily store the entire dataset before moving it to my S3 bucket (whose region is US East N. Virginia).
Just run in your bash these two lines to download the entire dataset with wget:
wget https://s3.amazonaws.com/nyc-tlc/trip+data/green_tripdata_20{13..16}-{01..12}.csv
wget https://s3.amazonaws.com/nyc-tlc/trip+data/yellow_tripdata_20{09..16}-{01..12}.csvThen, copy the file using AWS CLI S3 (speed about 100Mb/s):
aws s3 cp <DATASET_LOCAL_DIRECTORY> s3://<YOUR_BUCKET>/<YOUR_FOLDER>/ --recursiveThe entire process (download and copy the dataset) took me only around 2 hours.
Remove then all the files from your EC2 Instance.
Note: A EBS volume can only be increased, not decreased.
Structure folders inside the bucket
I personally structure folders inside my nyctaxidataset bucket as follow:
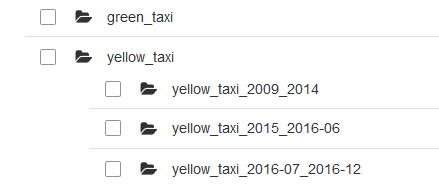
The whole dataset structured in folders
This is because starting from 2015, a new field (improvement_charge) appears in the files, and starting from July of 2016, instead of having the longitude and latitude of the pickup and dropoff places, there are two fields (PULocationId and DOLocationId) which contains integer that point to an area ID. That's why I distinguish these files into 4 folders that will later be loaded in Hive tables.
The total size of the dataset is 215 GB.
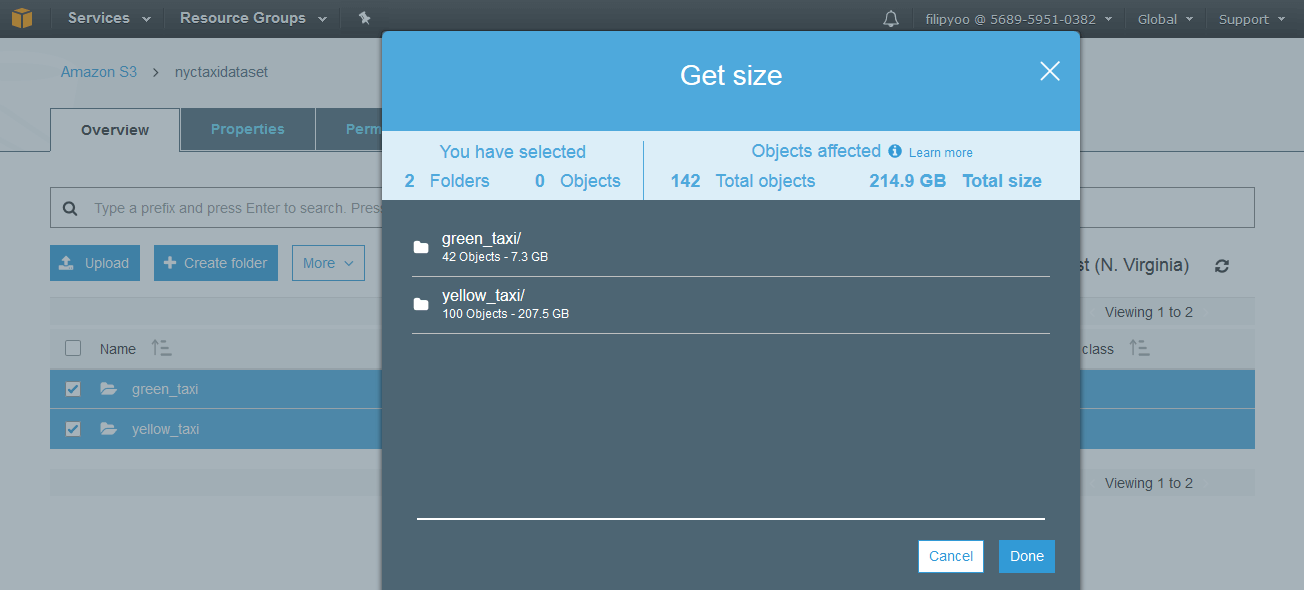
Total size of the entire dataset: 215 GB
Installing Cloudera Manager
Now that the dataset is download, we need to deploy a Hadoop cluster to analyze it. Amongst the EC2 instances, choose one to be the Cloudera Manager host, which is not necessarily the Master node. Then, run the following:
wget http://archive.cloudera.com/cm5/installer/latest/cloudera-manager-installer.bin
sudo su
chmod +x cloudera-manager-installer.bin
./cloudera-manager-installer.bin
Follow the installation instructions and go then to <public_DNS_IP:7180> and enter admin and admin as the ID and password.
Click on Continue, then enter the public IP of all your nodes, then don't choose the Single User Mode. Choose Packages (and not Parcels, some bugs might occur if you don't have a supported OS) and the latest CDH.
When you're asked to provide SSH login credentials, choose Login To All Hosts as: Another user, and choose ubuntu (depending on your OS). Choose then for Authentification Method: All hosts accept same private key. This is important when you work on the cloud and not on-premise. Choose then the same .pem file you use when creating your EC2 instances. Don't set a Passphrase, and click on Continue.
You should then see the packages installing on each of your nodes like this:
Once done, you are going to be asked to choose which services to install in your cluster. Just choose All Services, which include everything in the CDH (HDFS, YARN, ZooKeeper, Oozie, Hive, Hue, Spark etc...). Then, you'll be asked to assign roles to each node in the cluster. Keep it at it is, or you can choose your master to be also the Cloudera Manager host (by default, Cloudera choose randomly the Master node)
Installing all the services requires a minimum of ~10 Gb, so it's safe to have at least 20 Gb on your attached EBS (I had to resize mine because I only had 8Gb). Keep on clicking Continue, and after a while, your cluster will be ready with all the services installed and distributed across the cluster !
Connect your S3 to your Hadoop Cloudera cluster
Unlike an on-premise Hadoop cluster where HDFS is used and data is replicated across the cluster on DataNodes, a native cloud-based cluster don't need HDFS to work. Indeed, you have to either attach to your EC2 instance EBS volume for the persistent storage (which is costly and the total size of the whole dataset must be duplicated due to the replicated nature of HDFS) or volatile EC2 that disappear when stopping the instances.
This and this article describe the benefits of using S3 over HDFS for a cluster in the cloud.
Thanks to S3's durability, data don't need to be replicated to keep data integrity.
To connect your S3, in the Cloudera Manager home page, go to AWS credentials.
Choose a name, enter your Access and secret access key. Choose then to Enable S3Guard, to guarantee a consistent view of data stored in your S3 (additional fee might be applied).
Then, choose enable Cluster Access to S3.
You should then see the S3 Connector icon on your Cloudera Manager home page.
The next step is to enable Hue and Hive to access to your S3. To do so, from the Cloudera Manager home page, go to Configuration > Advanced Configuration Snippets, choose Hue filter on the left, and add your AWS credentials as follow:
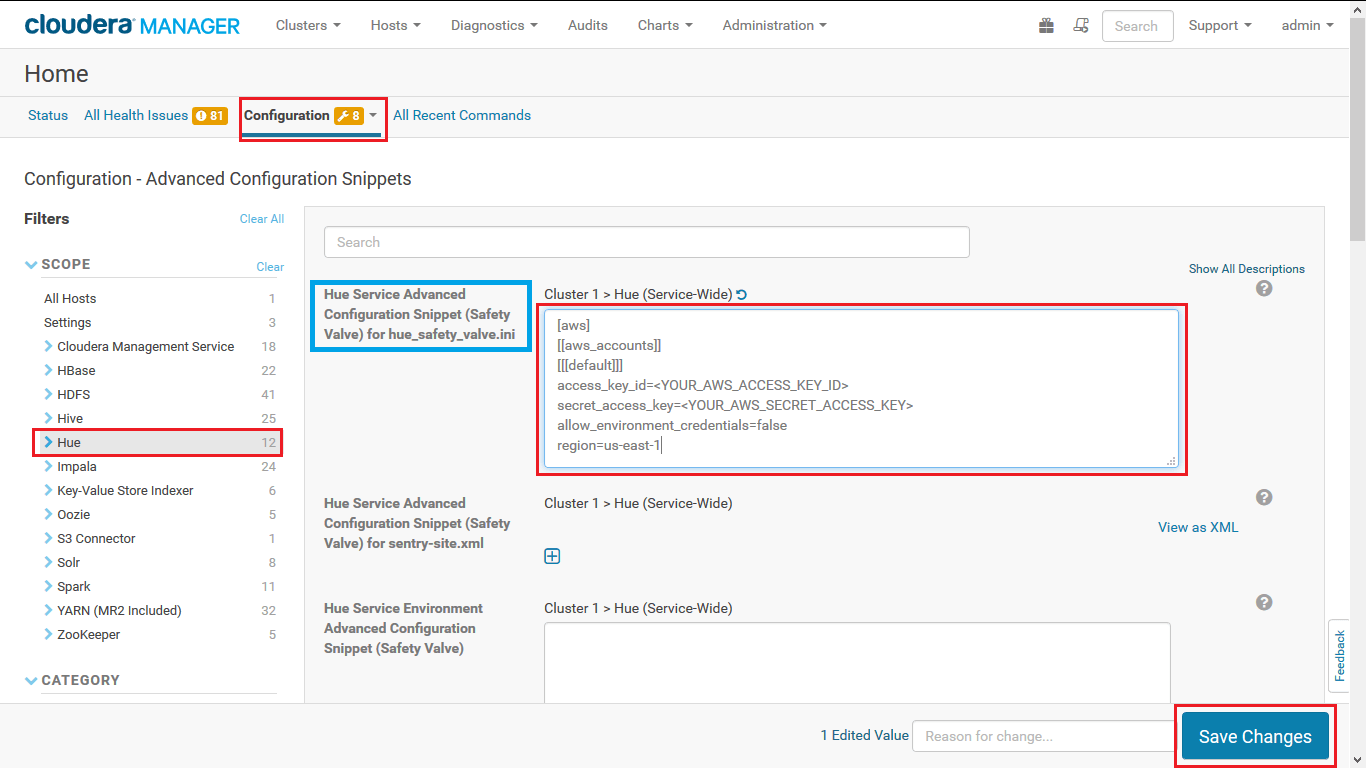
Save your changes, and clear all the filter, then search for core-site.xml. In the Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml and Hive Service Advance Configuration Snippet (Safety Valve) for core-site.xml, the following:
<property>
<name>fs.s3a.access.key</name>
<value><YOUR_AWS_ACCESS_KEY_ID></value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value><YOUR_AWS_SECRET_ACCESS_KEY_ID></value>
</property>Save your changes, and restart Hive and Hue services as follow:
Create Hive tables from the dataset using Hue Web UI
Once you're done with the previous step, you're able to see your S3 buckets in the Hue Web UI by going to Hue > Web UI > Hue Loaded Balanced - recommended tab.
Then, enter a user name and password for your first use. In the Browsers tab, you should now see the S3 tab from where you can browse your buckets. Choose to write query with Hive via the Query tab.
Similarly to my S3 bucket, I create 4 Hive tables, each corresponding to a folder, here's an example to create the green taxi tab:
CREATE EXTERNAL TABLE green_taxi (
vendorID VARCHAR(3),
pickup_datetime TIMESTAMP,
dropoff_datetime TIMESTAMP,
store_and_fwd_flag VARCHAR(1),
ratecodeID SMALLINT,
pickup_longitude DECIMAL(9,6),
pickup_latitude DECIMAL(9,6),
dropoff_longitude DECIMAL(9,6),
dropoff_latitude DECIMAL(9,6),
passenger_count SMALLINT,
trip_distance DECIMAL(6,3),
fare_amount DECIMAL(6,2),
extra DECIMAL(6,2),
mta_tax DECIMAL(6,2),
tip_amount DECIMAL(6,2),
tolls_amount DECIMAL(6,2),
ehail_fee DECIMAL(6,2),
total_amount DECIMAL(6,2),
payment_type VARCHAR(3),
trip_type SMALLINT
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
LOCATION 's3a://nyctaxidataset/green_taxi/'
tblproperties("skip.header.line.count"="1");The key point here, is to use the EXTERNAL TABLE and the LOCATION keyword to point to your bucket location.
Querying more than 200 GB of data
Once the 4 tables created, I just wanted to test the query time when using a Hadoop cluster with only 3 DataNodes and 1 NameNode to count the total number of rows of all the tables.
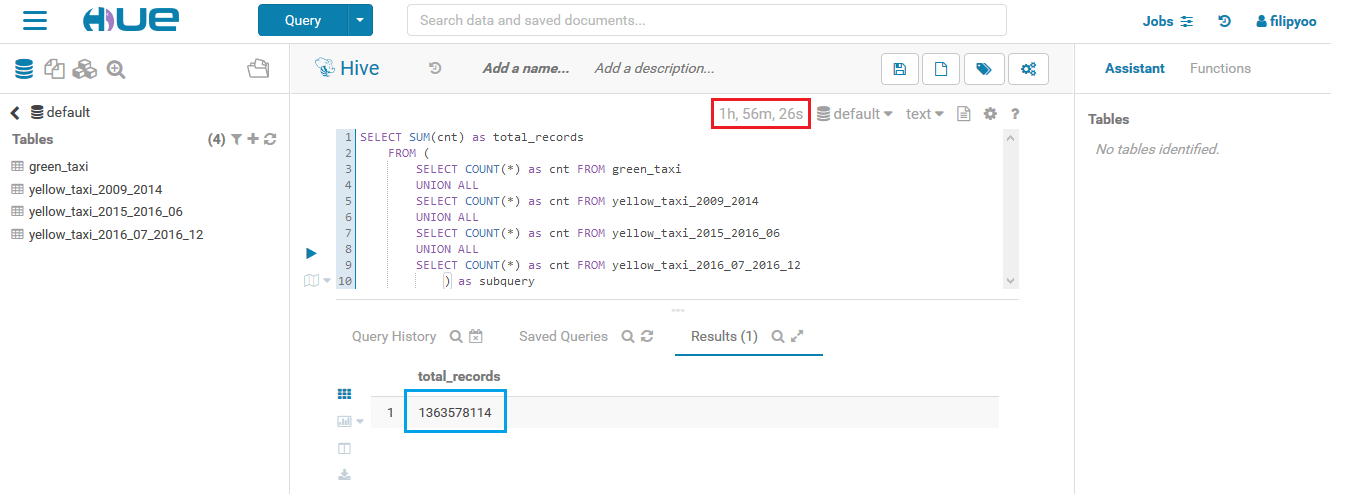
2 hours to count 1.3 billion rows with a 4-nodes cluster
It took 2 hours to count a little bit more than 1.3 billion rows of record with a cluster of 4 nodes.
Since Hive is built on top of the MapReduce component of the Hadoop ecosystem, each Hive query is actually turned into a MapReduce job.
So you can check the job detail in the Job tab like below:
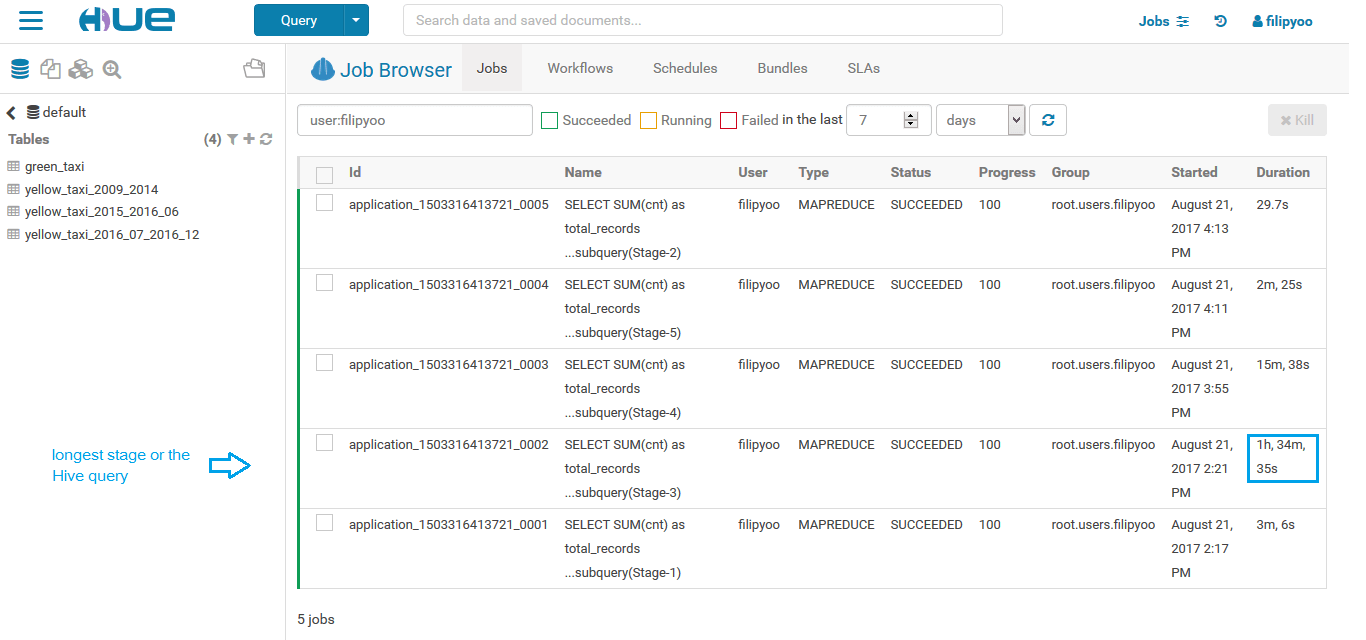
Here the stage that took the most time is the Stage-3 (4th line) which in fact counts rows of the yellow_taxi_2009_2014 table that points to a S3 folder which contains 170 GB within 72 CSV files.
You can also click on each individual job to see their details like this:
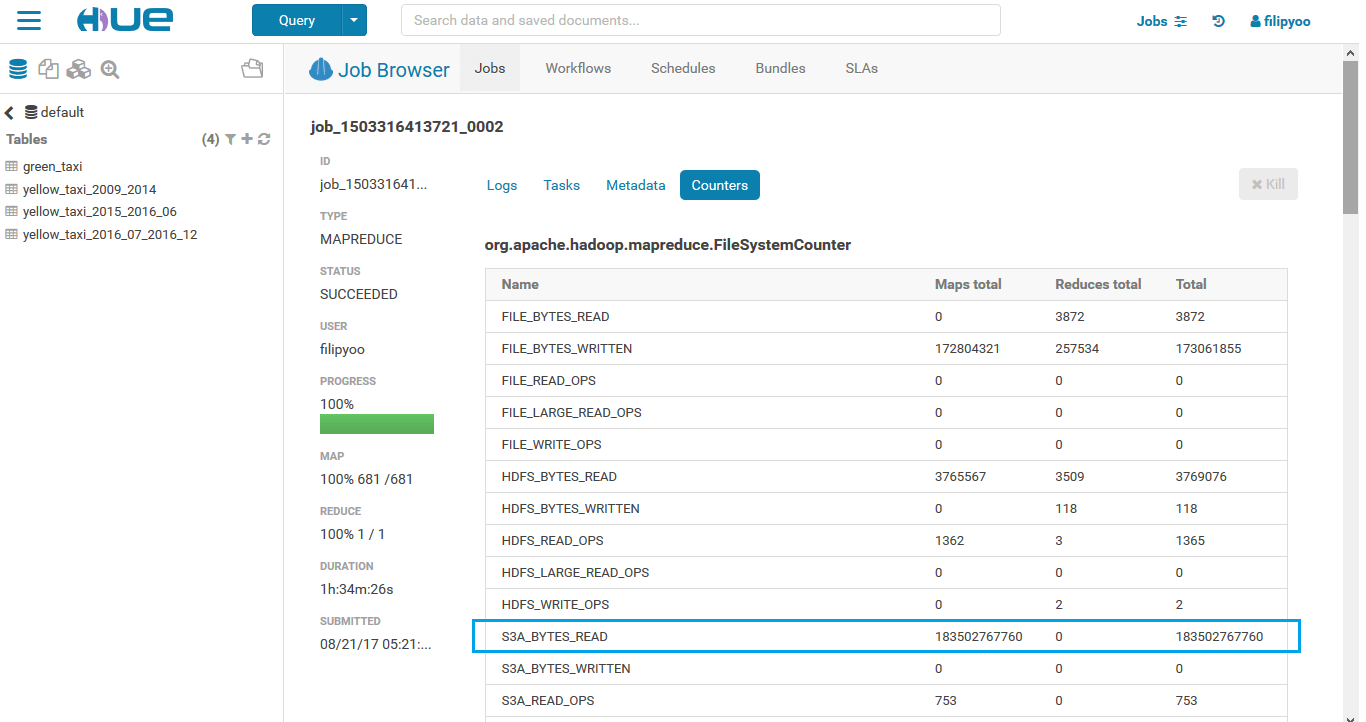
Here we can see that to count the entire yellow_taxi_2009_2014, more than 180 GB were read from S3 bucket, using the S3A URI scheme.
Of course, you can also check your job without Hue, just go to the <your_master_public_IP:8088>.
More nodes in cluster = faster query ?
Adding new hosts to existing cluster
The way Hadoop is built and the principe of the horizontal scalability suppose that the more DataNodes we have in the cluster, the better the IO performance and processing time. So to confirm this fact, I add up to my existing cluster 16 more EC2 instances DataNodes, which forms then a cluster with 20 nodes.
To add more hosts to the existing cluster, go to: Hosts > All Hosts > Add New Hosts to Cluster. The classic wizard will appear, then just repeat the previous steps.
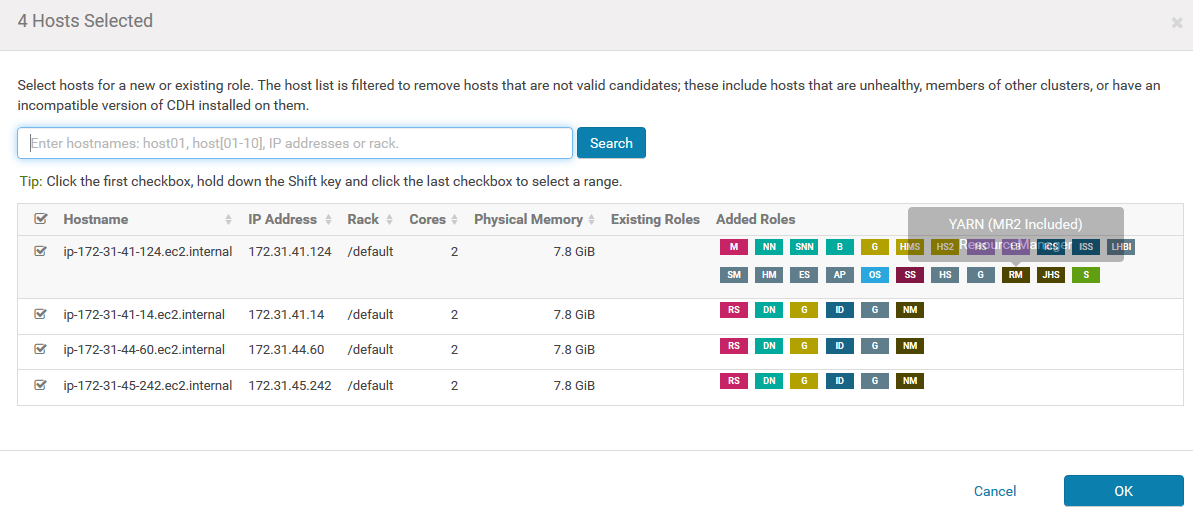
You then will be asked to use a host template, which basically allow you to have a specific number of roles assigned to the newly added hosts. Choose to create a template and choose the same services used by your existing DataNodes. Eventually you will have something like this:
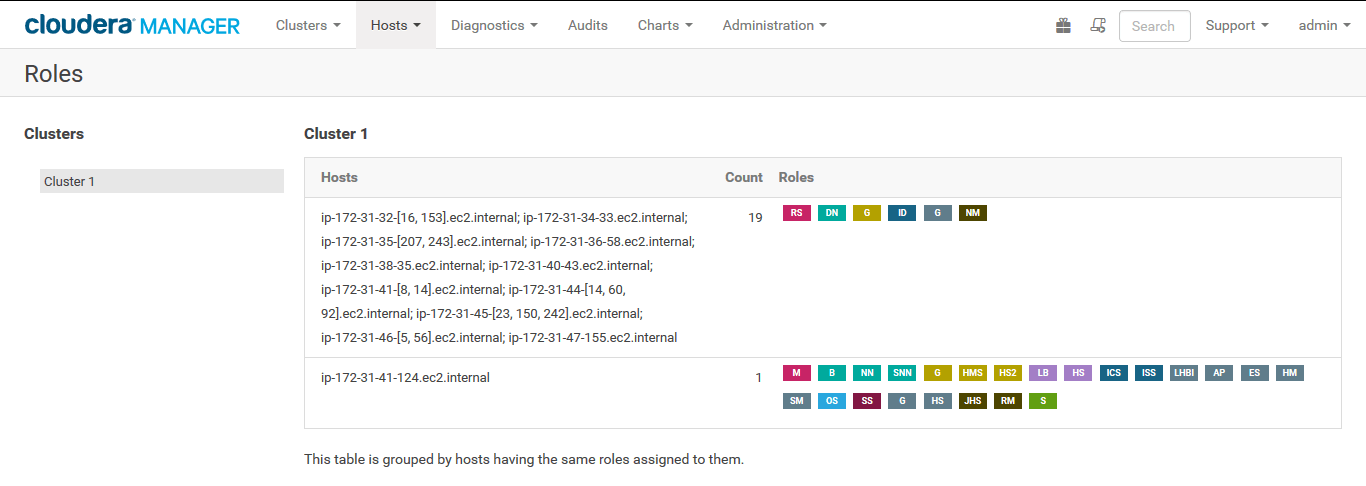
Restart then the cluster (Cluster > Restart) to get all the configuration distributed to all nodes.
Expected results
Here's the result with a cluster of 20 nodes:
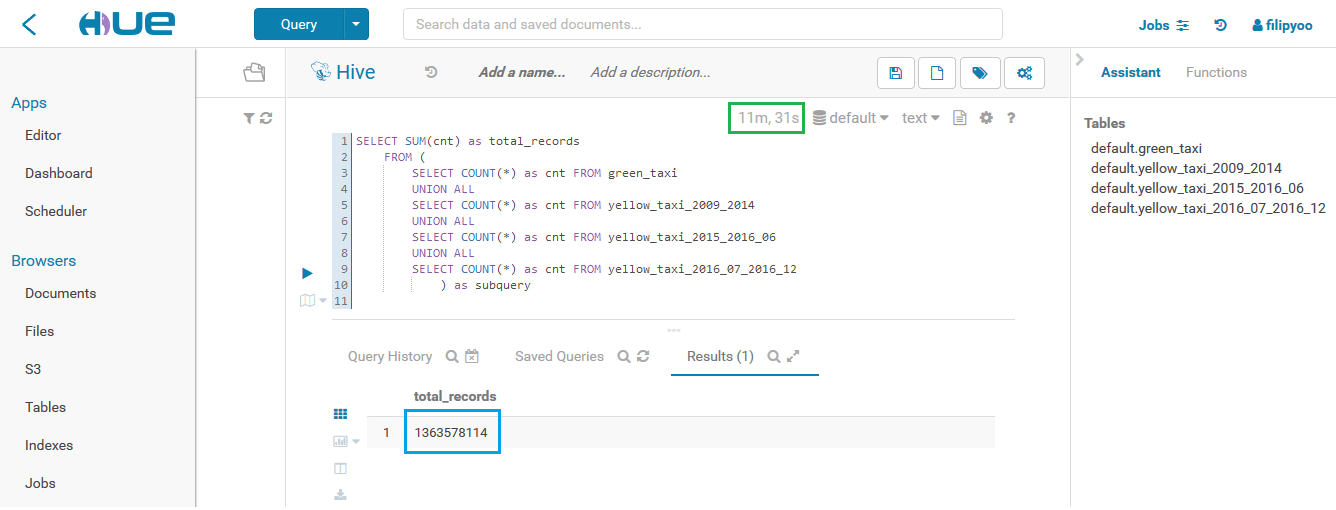
Only 11 minutes to count 1.3 billions rows with a 20-nodes cluster
As expected, with 20 nodes, the same counting rows query is waaaaay faster than a 4-nodes cluster. It only takes 11 minutes to count 1.3 billions rows, 10x faster.
Of course, using 20 m4.large EC2 instances is not free... But you have to be willing to pay a little bit to learn by yourself in the big data world and I think it's way more efficient to learn this way, by getting your hands on real world dataset and having your own process, instead of paying and following expensive online courses that teach you the basic with smaller dataset.
The next step now is to do a deeper analysis with the dataset.
For the complete code, please check my GitHub repository.




© 2020, Philippe Khin