

Nowadays, it's really easy to get information or reviews about a specific product, or what people might think about a topic. You can check reviews on a merchant site or an online shopping site like Amazon or others. Alternatively, you can also hear from people think about a product on social networks, because people tend to express their feelings quickly through Twitter or Facebook, rather than bother themselves to write reviews on a specific website. An example of this, is the American election. You can see what millions of people think about a particular candidate by analyzing they say on their tweets.
So, I did an analysis about a famous video game released recenlty. Being a great fan of Final Fantasy XV, I wanted to know how people think about it before bying it. So naturally, I choose to use Twitter and its Streaming API to get real-time tweets from people around the world and analyze their tweets. First, you have to register in order to get an API key before being able to use the Twitter API to fetch the streaming tweets. I used for this study, Tweepy, the Twitter API for Python that supports their streaming API. Here's the part of the code which fetchs streaming tweets related to a topic you speficy with keywords :
import tweepy
consumer_key = '<YOUR_CONSUMER_KEY>'
consumer_secret = '<YOUR_CONSUMER_SECRET_KEY>'
access_token = '<YOUR_ACCESS_TOKEN>'
access_token_secret = '<YOUR_ACCESS_TOKEN_SECRET>'
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
myStreamListener = MyStreamListener()
myStream = tweepy.Stream(auth = api.auth, listener=myStreamListener)
myStream.filter(track=['ffxv', 'ff xv', 'ff15', 'ff 15', 'final fantasy xv', 'final fantasy 15'])So your MyStreamListener class will handle the streaming tweets. The response for the API call is returned in JSON format, and what we want to do, is to store not all, but specific and useful fields of the JSON response in a SQL table in order to analyze the database for further process. Processing or storing the streaming tweets should be done inside the MyStreamListener within the method on_data. Here are the fields I choose to store and how MyStreamListener now looks like :
class MyStreamListener(tweepy.StreamListener):
def on_status(self, status):
print(status.text)
def on_error(self, status):
print(status)
def on_data(self, data):
all_data = json.loads(data)
created_at = all_data['created_at']
favorite_count = all_data['favorite_count']
favorited = all_data['favorited']
filter_level = all_data['filter_level']
lang = all_data['lang']
retweet_count = all_data['retweet_count']
retweeted = all_data['retweeted']
source = all_data['source']
text = all_data['text']
truncated = all_data['truncated']
user_created_at = all_data['user']['created_at']
user_followers_count = all_data['user']['followers_count']
user_location = all_data['user']['location']
user_lang = all_data['user']['lang']
user_name = all_data['user']['name']
user_screen_name = all_data['user']['screen_name']
user_time_zone = all_data['user']['time_zone']
user_utc_offset = all_data['user']['utc_offset']
user_friends_count = all_data['user']['friends_count']
conn = sqlite3.connect('healthy_food.db')
c = conn.cursor()
c.execute('''INSERT INTO tweets
(created_at, favorite_count, favorited, filter_level, lang,
retweet_count, retweeted, source, text, truncated, user_created_at,
user_followers_count, user_location, user_lang, user_name,
user_screen_name, user_time_zone, user_utc_offset, user_friends_count)
VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)''',
(created_at, favorite_count, favorited, filter_level, lang, retweet_count,
retweeted, source, text, truncated, user_created_at,
user_followers_count, user_location, user_lang, user_name,
user_screen_name, user_time_zone, user_utc_offset, user_friends_count))
conn.commit()
conn.close()I let the program run for a few hours and finally got about 12 000 tweets.
We can now write some basics query to see for instance, what users tweeted the most during these few hours about Final Fantasy XV.
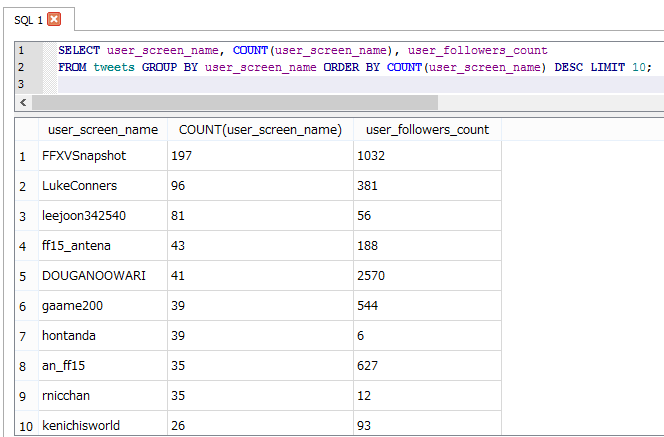
Since Final Fantasy XV is a Japanese game, we can expect that a great part of the user who tweets about this, are Japanese. The data confirm this hypothesis.
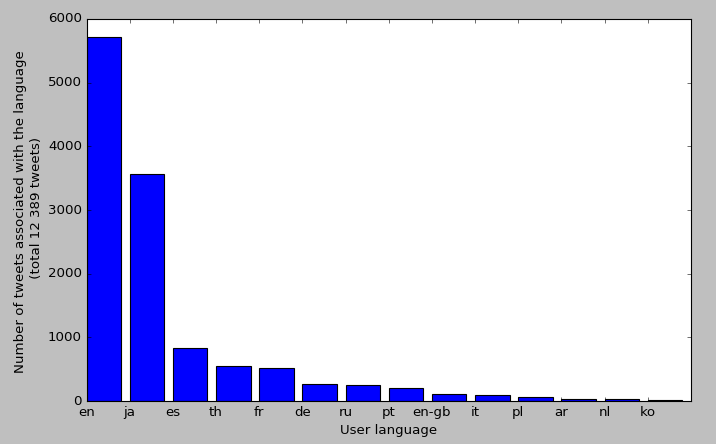
Almost half of the tweets are from users who defined English as their language, and a quarter of them are Japanese.
Before proceeding to sentiment analysis on the tweets, they have to be cleaned. Indeed, not useful information such as URL, hashtags or retweet users should be deleted from each tweet. I did this by using some Regular Expression and since Twitter use a URL shortener, it's really simple to get a matching URL pattern :
def cleanTweetText(tweet):
retweet_rx = re.compile(r'RT @\w+:\s')
url_rx = re.compile(r'https://\w\.\w+/\w+')
hashtag_rx = re.compile(r'#\w+\s')
to_user_rx = re.compile(r'@\w+\s')
regex = [retweet_rx, url_rx, hashtag_rx, to_user_rx]
for rx in regex:
tweet = re.sub(rx, '', tweet)
return tweetThe next thing interesting to see is the most hashttaged word. Two ways to do this, the first is creating a dictionnary of frequency and print out the most used hashtag as the following :
def getHashtag(tweet):
# return list of hashtags
hashtag_rx = re.compile(r'#\w+')
hashtags = hashtag_rx.findall(tweet)
return hashtags
def getAllHashtags(all_tweets):
all_hashtags = []
for tweet in all_tweets:
hashtags_list = getHashtag(tweet[0])
all_hashtags.extend([h for h in hashtags_list])
return all_hashtags
def countHashtag(hashtags_list):
# return a dict hashtag/frequency pair
hashtags_freq = defaultdict( int )
for h in hashtags_list:
hashtags_freq[h.lower()] += 1
return dict(hashtags_freq)
def printMostFrequentHashtags(nb_most_hashtagged, all_hashtags):
hTag_freq_dict = countHashtag(all_hashtags)
most_Htag_values = sorted(list(hTag_freq_dict.values()), reverse=True)[:nb_most_hashtagged]
for i in most_Htag_values:
print (list(hTag_freq_dict.keys())[list(hTag_freq_dict.values()).index(i)])
all_hashtags = getAllHashtags(all_tweets)
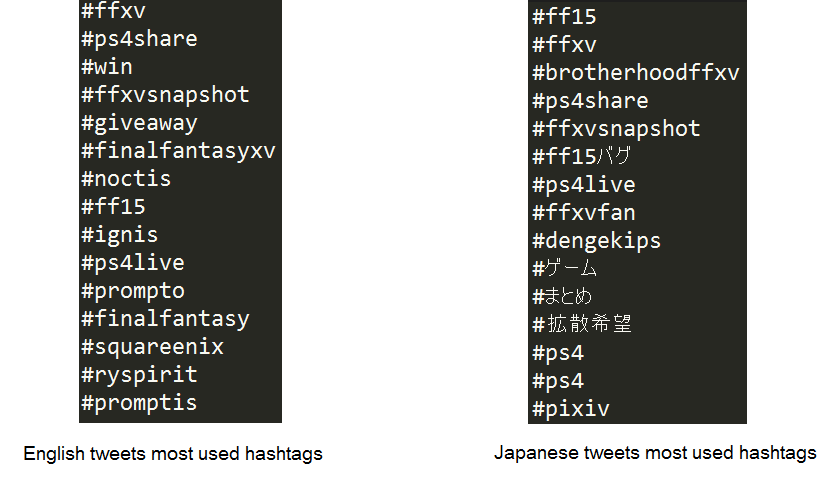
printMostFrequentHashtags(15, all_hashtags)And here's the result for English tweets and Japanese :
Another way to visualize this, is to create a wordcloud. There's a great library for Python called WordCloud, which allows you to easily create a wordcloud. Here are the few lines that enables the creation of the word cloud :
def createWordCloud(all_hashtags_list):
wordcloud = WordCloud(font_path='C:\Windows\Fonts\AozoraMinchoBlack.ttf',
width = 1000, height = 500).generate(' '.join(all_hashtags_list))
plt.figure(figsize=(15,8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()I had to specify my own Japanese font path for Japanese font support.
And here's the word cloud for the English tweets :
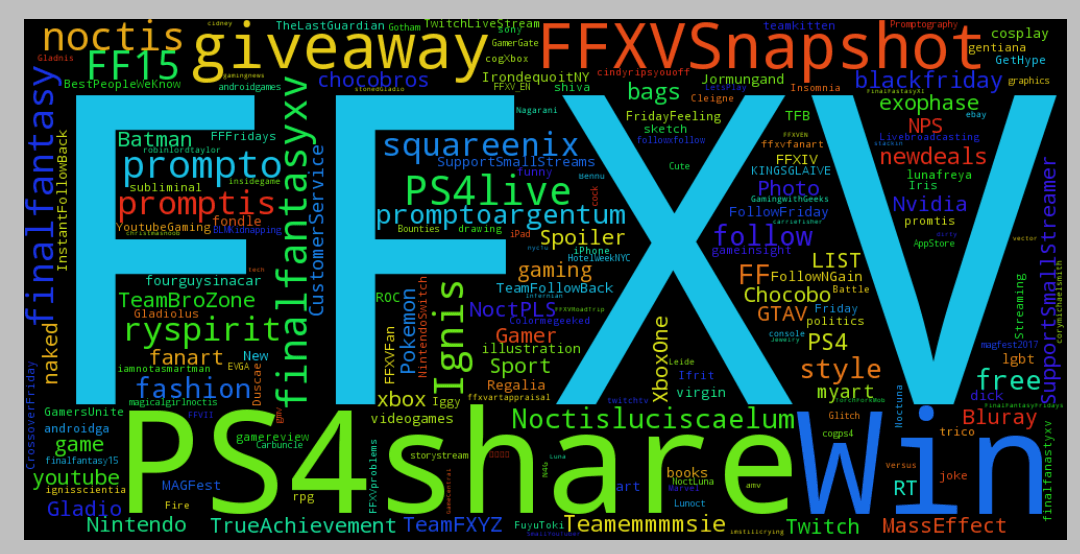
As for the sentiment analysis, many options are availables. Either you can use a third party like Microsoft Text Analytics API or Sentiment140 to get a sentiment score for each tweet. As for me, I use the Python TextBlob library which comes along with a sentiment analysis built-in function. Here's the code to get and plot the sentiment of each English tweet with its polarity and subjectivity :
def getTweetSentiment(all_tweets):
for tweet in all_tweets:
cleaned_tweet = cleanTweetText(tweet[0])
tweet_sentiment = TextBlob(cleaned_tweet).sentiment
yield tweet_sentiment
def plotSentiment():
polarity = []
subjectivity = []
for sentiment in getTweetSentiment(all_tweets):
polarity.append(sentiment.polarity)
subjectivity.append(sentiment.subjectivity)
plt.scatter(polarity, subjectivity, c=polarity, s=100, cmap='RdYlGn')
plt.xlabel('Tweet polarity')
plt.ylabel('Tweet subjectivity')
plt.xlim(-1.1, 1.1)
plt.ylim(-0.1, 1.1)
plt.show()
positive_polarity = [p for p in polarity if p>0]
negative_polarity = [n for n in polarity if n<0]
neutral_polarity = [r for r in polarity if r==0]
total_size = len(positive_polarity) + len(negative_polarity) + len(neutral_polarity)
n_size = len(negative_polarity)/total_size
p_size = len(positive_polarity)/total_size
r_size = len(neutral_polarity)/total_size
labels = ['Neutral tweets', 'Positive tweets', 'Negative tweets']
sizes = [r_size, p_size, n_size]
fig1, ax1 = plt.subplots()
ax1.pie(sizes, labels=labels, autopct='%1.1f%%',
shadow=True, startangle=90)
ax1.axis('equal')
plt.show()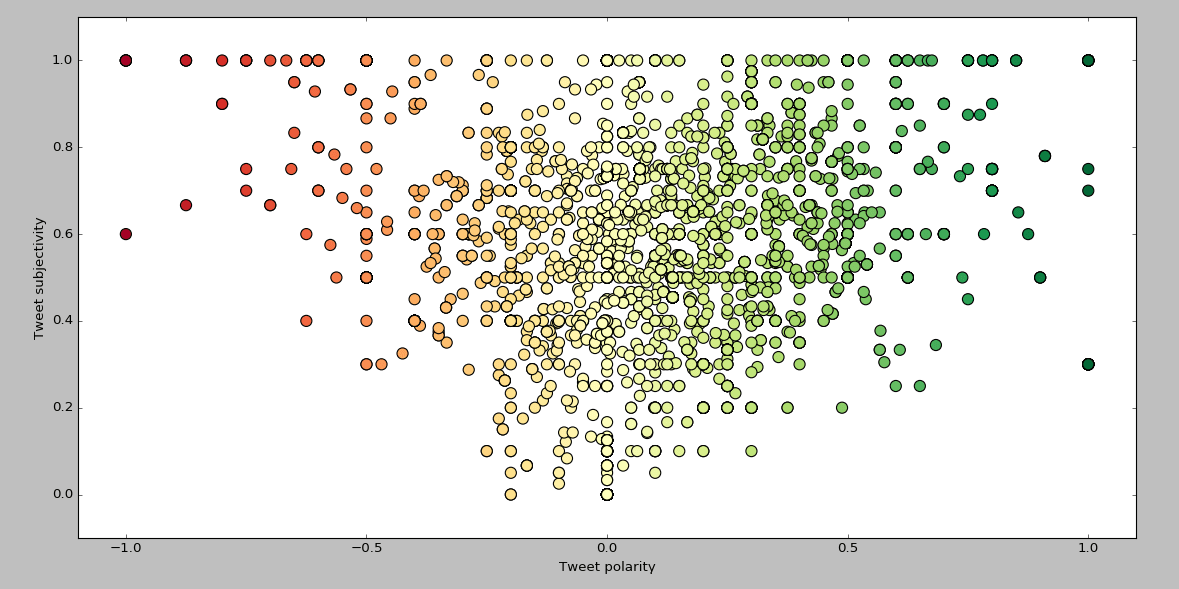
Plot of tweet sentiment according to their polarity and subjectivy. The greener the point, the more positive the tweet is.
And the pie graph of the percentage of negative, neutral and positive tweets :
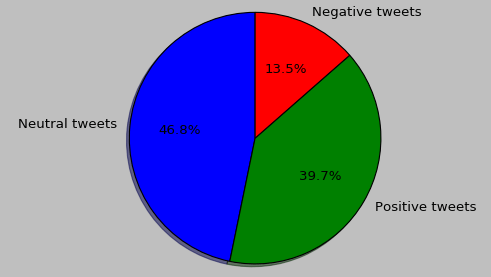
Seems like Final Fantasy XV get more positive feeling than negative ones, maybe should I consider buying it ? =D
Other things that can be done are for instance getting the word cloud of the most used words. I did it using Python NLTK library but the result is a picture similar to the previous word cloud, so I won't post it here.
For the complete code, please check my GitHub repository.
This topic and sentiment analysis can be done with any topics you would like to know, like a specific movie, topics like healthy food etc...




© 2020, Philippe Khin