
It's sometime useful to have all the posts of an user or articles of your favourite blog stored on your PC, so you can read them offline, or manipulate them, such as creating a GUI to read them instead of just reading them from a .txt file.
I personnally use Lang8, which is a new language learning platform where native speakers correct what you write. It really helps me in learning Japanese. Not only you can write your own posts and get corrected by native speaker, but you can also read other native speaker posts.
So, I'm following a native Japanese user (yamasv), who posts on a regular basis, Japanese sentence, grammar usages in both Japanese and English (he wants to improve his English skills). To see a user's post, you have to sign up.
Here's an example of a post :
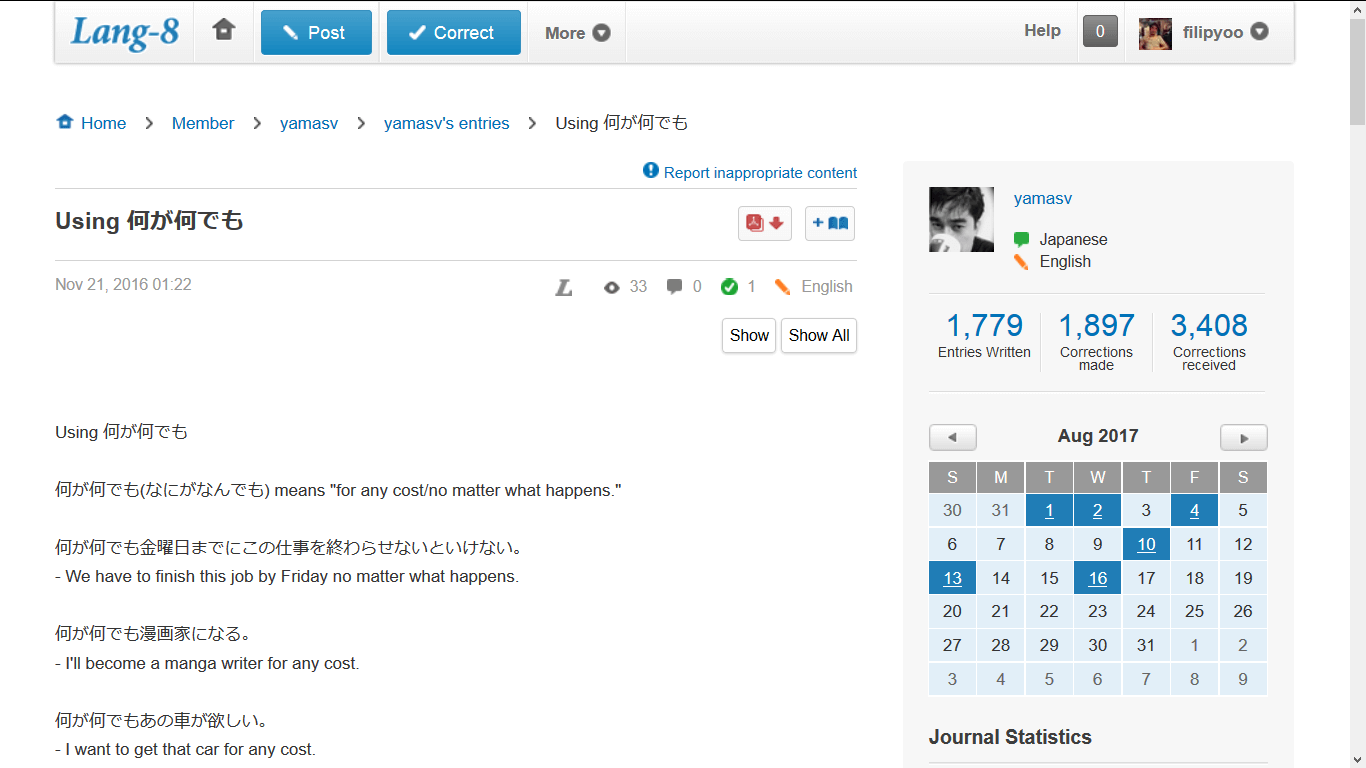
So, when an user has like over 1500 entries, it's really hard to remember which post you have read the last time, on which page, because as the post number grows up. the number of page also increases.
First let's look at the code :
from selenium import webdriver
import bs4, sys, os, time
def login(browser, login_url):
browser.get(login_url)
browser.maximize_window()
browser.implicitly_wait(1)
userNameElem = browser.find_element_by_id('username')
userNameElem.send_keys(myUserName)
passwordElem = browser.find_element_by_id('password')
passwordElem.send_keys(myPassword)
passwordElem.submit()
time.sleep(1)
# without waiting, the website doesn't have time to log in et register the information.
#USING PHANTOMJS for headless browsing (without opening a mozilla window)
phantomJS_path = '<your_path_to_phantomjs.exe>'
browser = webdriver.PhantomJS(phantomJS_path)
# LOG in lang8
login_url = "https://lang-8.com/login"
yamasvPage = "http://lang-8.com/605858/journals?page=" # your interested user profile page
login(browser, login_url)
entry_index = 1 # this will be the name of your .txt file
first_page = 1
last_page = 83
print ("Start downloading....\n")
for page_index in reversed(range(first_page, last_page+1)):
print ("Now downloading page: " + str(page_index))
browser.get(yamasvPage + str(page_index))
entries_page = browser.page_source
soup = bs4.BeautifulSoup(entries_page,"lxml")
entries_elem = soup.select('.journal_title a')
for entry in reversed(entries_elem):
entry_link = entry.get("href")
browser.get(entry_link)
entry_page = browser.page_source
soup = bs4.BeautifulSoup(entry_page,"lxml")
entry_text = soup.select('#body_show_ori')
entry_text = str(entry_text[0]).replace("<div id=\"body_show_ori\">", "") \
.replace("</div>","").replace("<br/>","\n")
f = open("yamasvEntries\\" + str(entry_index) + ".txt","w", \
encoding="utf-8")
f.write(entry_text)
f.close()
entry_index = entry_index + 1
print ("\n----------------------------------\n")
print("DONE downloaded all entries.\n")So what I did here, is to use a library called BeautifulSoup, Selenium and PhantomJS (for headless browsing (without opening a mozilla window).
This code's gonna use the selenium webdriver, and we navigate through a headless browser PhantomJS, then parse parse HTML content with BeautifulSoup.
The code will go through each entries page, which contains 20 posts. For each page, it will "click" on each entry post, and parses its HTML source code, and clean the HTML tags to get only the text.
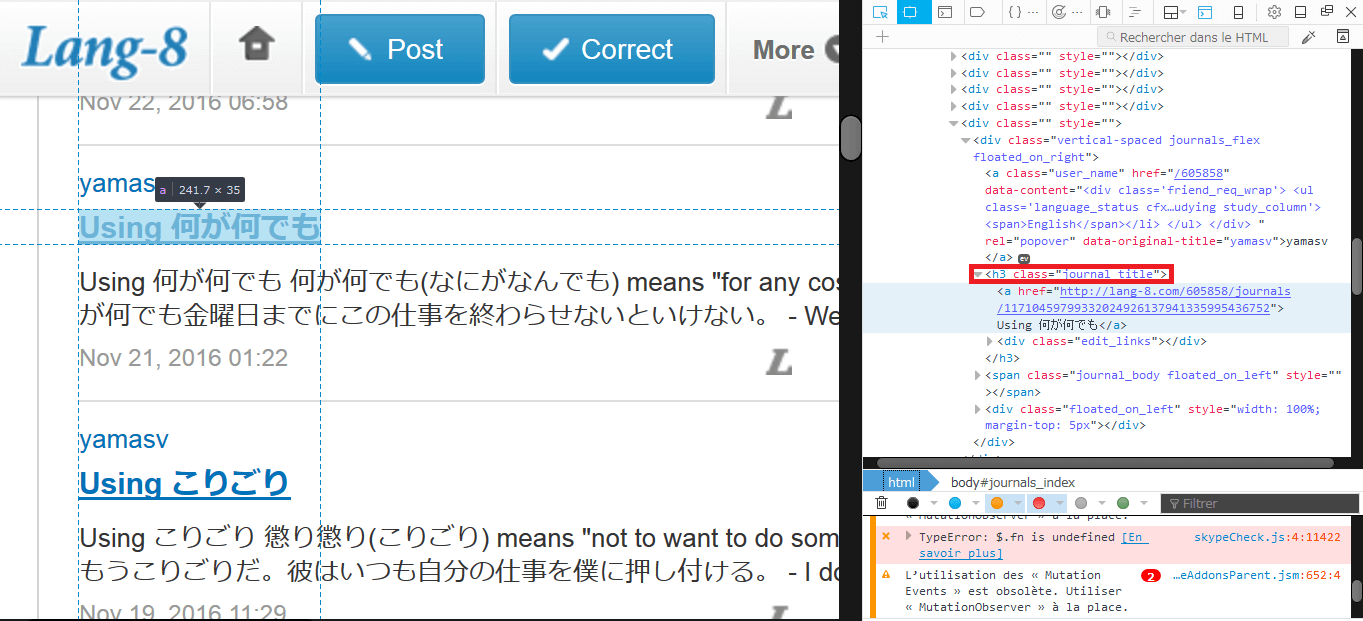
The key to webscraping is to first analyse the HTML code of your interested website. But it doesn't require that hard work, all you have to do, is to right click and choose Examine this element, on the element you want to analyse, for example for me the title of each entry post that I have to "click" on is located in a "journal_title" class.
Then on the page of each individual post, we have :
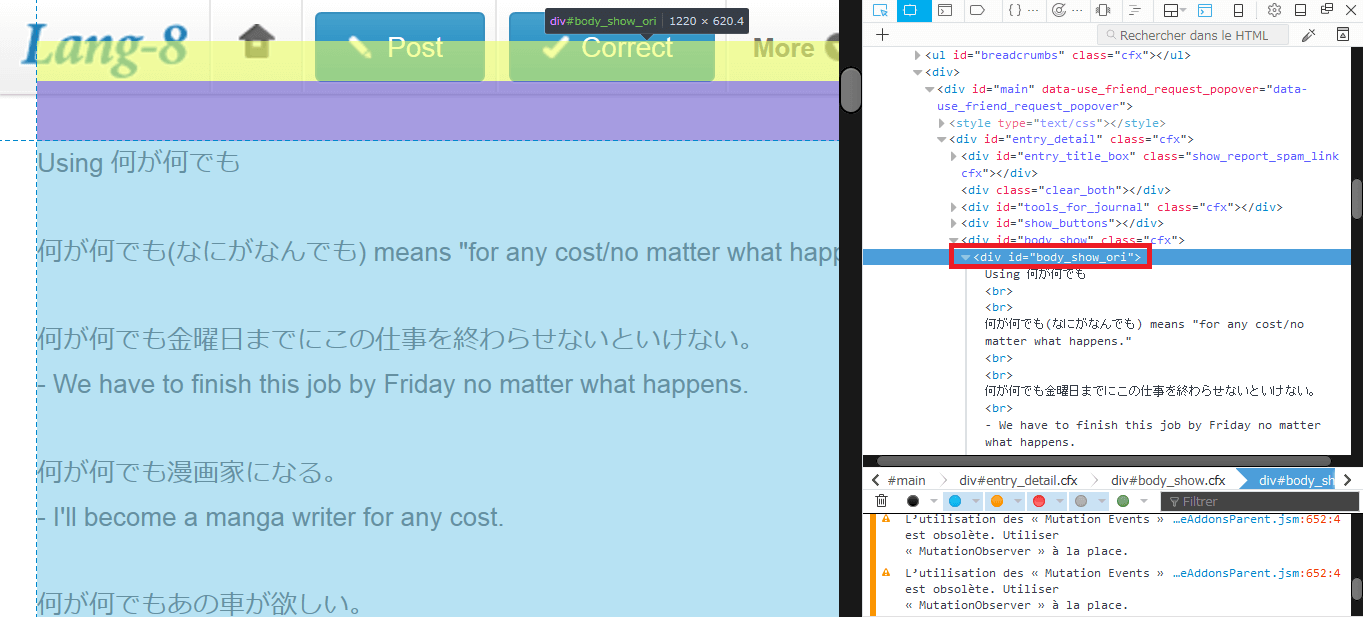
You can see, that the 'journal_title' class and the 'body_show_ori' id are the one used in the code.
Then, the text will be written in a file whose name is the number of this entry, the greater number is the latest post like 1524.txt, and 1.txt is the oldest post. You also can choose from which page to which page to download the content. Here's what we get on the file for example 1657.txt on the previous screenshot :
So after launching this script, you get a folder filled with all your favourite user posts stored in a file txt !
Next post, we gonna see how to deal with all these text files, by building a Python GUI application, to read each individual posts, or select the entry you wanna read !
Download the app
And if you are interested, here is the APK file for the simple Android application to read these entries, described in this post.
All credit goes to yamasv, I post the app here with his approval :)
For the complete code, please check my GitHub repository.




© 2020, Philippe Khin